Lập trình Machine Learning-Python
Lập trình Machine Learning là dùng ngôn ngữ lập trình, sử dụng các thuật toán trong toán học để làm cho Máy học (máy tính, máy móc, thiết bị…) có thể học từ những dữ liệu và phân tích các dữ liệu sau đó học cách dự đoán và đưa ra kết quả.
Có nhiều ngôn ngữ lập trình cho Machine Learning và AI.Tuy nhiên ngôn ngữ Python là một ngôn ngữ lý tưởng, có thư viện lớn hỗ trợ lập trình Machine Learning và AI.
Bạn muốn lập trình Machine Learning với Python nhưng không biết bắt đầu từ đâu ?Bài này chúng tôi sẽ hướng dẫn sử dụng ngôn ngữ Python để lập trình Machine Learning.
Làm thế nào để bắt đầu lập trình Machine Learning trong Python ?
Cách tốt nhất để học lập trình machine learning là tạo một dự án project nhỏ và thực hiện các bước cơ bản từ đầu tới cuối của project.
Một dự án về Machine Leaning thường bao gồm các phần sau:
- Chuẩn bị dữ liệu, tập dữ liệu Dataset.
- Phân tích,xử lý dữ liệu dựa vào các thuật toán
- Đánh giá kết quả trên các thuật toán khác nhau.
- Đưa ra dự đoán kết quả.
Trong phần này chúng tôi sẽ hướng dẫn bạn tạo một dự án nhỏ project và cách cài đặt các công cụ, thư viện cần thiết để lập trình machine learning.
Các bước tạo project Machine Learning trong Python:
Sau đây là các bước tạo một project về Machine Learning trong Python:
1. Download và cài đặt phần mềm, thư viện Python.
2. Kiểm tra phiên bản phần mềm và các thư viện Python.
3. Import các thư viện cần thiết vào dự án.
4. Load dữ liệu và tập dữ liệu dataset.
5. Phân tích, xử lý dữ liệu dataset
6. Data Visualization: Biểu diễn dữ liệu trực quan bằng đồ thị.
7. Train/Test Model và Evaluate Some Algorithms : Xây dựng hình dữ liệu Model và sử dụng các thuật toán để đào tạo và kiểm tra Model.
8. Make Predictions: Đánh giá các thuật toán và đưa gia dự đoán kết quả.
1. Download tải và cài đặt phần mềm và thư viện Python
1.1 Cài đặt Python:
Tải file cài đặt Python tại trang web : https://www.python.org/downloads/
Các bước cài đặt phần mềm Python bạn có thể tham khảo tại link sau: https://ihoclaptrinh.com/cai-dat-python-trong-windows-10
1.2 Cài đặt thư viện để lập trình machine learning
Có 5 thư viện chính cần cài đặt để lập trình machine learning.
Scipy.
Numpy.
Matplotlib.
Pandas.
Sklean.
Cài đặt thư viện Scipy như sau:
pip install scipy
Cài đặt thư viện Numpy như sau:
pip install numpy
Cài đặt thư viện Matplotlib như sau:
pip install matplotlib
Cài đặt thư viện Pandas như sau:
pip install pandas
Cài đặt thư viện Sklearn như sau:
pip install sklearn
2. Kiểm tra phiên bản Python và thư viện đã cài đặt.
Việc kiểm tra phiên bản và môi trường của Python là một việc cần thiết và nên làm khi bạn bắt đầu một dự án.Bởi vì sau khi cài đặt bạn cần kiểm tra xem phần mềm và thư viện đã cài đặt thành công hay chưa? Phiên bản có phù hợp với môi trường hay không để tránh gặp các lỗi trong dự án project.
Câu lệnh và cú pháp để kiểm tra phiên bản của thư viện như sau:
Ví dụ
# Kiểm tra phiên bản Python
import sys
print('Python: {}'.format(sys.version))
# Kiểm tra phiên bản scipy
import scipy
print('scipy: {}'.format(scipy.__version__))
# Kiểm tra phiên bản numpy
import numpy
print('numpy: {}'.format(numpy.__version__))
# Kiểm tra phiên bản matplotlib
import matplotlib
print('matplotlib: {}'.format(matplotlib.__version__))
# Kiểm tra phiên bản pandas
import pandas
print('pandas: {}'.format(pandas.__version__))
# Kiểm tra phiên bản scikit-learn
import sklearn
print('sklearn: {}'.format(sklearn.__version__))
Kết quả :
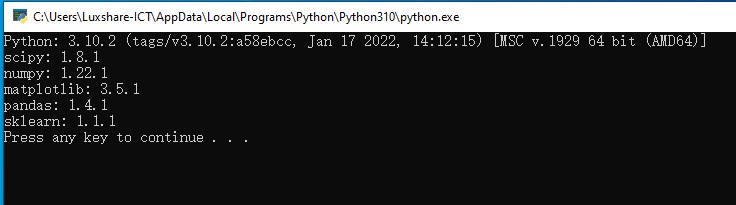
3. Import thư viện vào project
Khi lập trình Machine Learning bạn cần phải Import các thư viện, module sau:
Ví dụ
# Load libraries
from pandas import read_csv
from pandas.plotting import scatter_matrix
from matplotlib import pyplot
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import StratifiedKFold
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
4. Load dữ liệu (Load Dataset)
Sau khi cài đặt thư viện thành công, bước tiếp theo là chúng ta cần làm là sẽ tải dữ liệu.
Ở đây tôi sẽ sử dụng tập dữ liệu iris flowers làm dữ liệu đầu vào.Tôi sử dụng tập dữ liệu iris flowers này là bởi vì đây là một tập dữ liệu nổi tiếng, nó được sử dụng như chương trình “Hello Word” trong lập trình Machine Learning.Tập dữ liệu dataset này chứa 150 dòng 5 cột tương ứng 150 mẫu của hoa iris.
Bạn có thể tải dữ liệu trực tiếp từ kho lưu trữ dữ liệu UCI Machine Learning hoặc bạn có thể tải download file iris.csv về máy tính của bạn sau đó load dữ liệu từ máy tính. Trong phần này tôi lấy dữ liệu dataset trực tiếp từ kho lưu trữ dữ liệu UCI Machine Learning làm ví dụ.
Để load dữ liệu, trong python sử dụng thư viện pandas để load dữ liệu và phân tích dữ liệu.
Ví dụ
# Load dữ liệu dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
5. Phân tích, xử lý dữ liệu dataset
Sau khi load dữ liệu thành công bây giờ là đến lúc chúng ta có thể xem, khai thác, khám phá và xử lý dữ liệu và thống kê dữ liệu.
5.1 Xem dữ liệu vừa tải về.
Ví dụ xem dữ liệu của 15 dòng đầu tiên hoặc xem tất cả dữ liệu của datatset đã tải về như sau:
Ví dụ
# Xem dữ liệu của 30 dòng đầu tiên.
print(dataset.head(15))
# Xem tất cả dataset
print(dataset)
Kết quả :
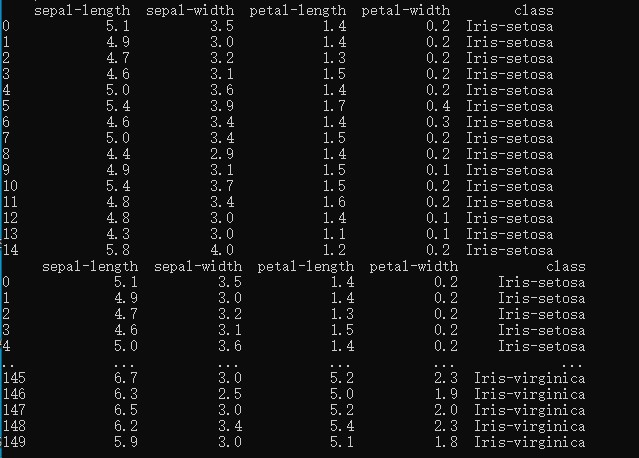
5.2 Kiểm tra và xem kích thước của tập dữ liệu dataset.
Sử dụng thuộc tính shape để kiểm tra kích thước của tập dữ liệu có bao nhiêu dòng và bao nhiêu cột.
Ví dụ
# Sử dụng shape để xem kích thước của tập dữ liệu
print(dataset.shape)
Kết quả :
(150, 5)
5.4 Thống kê các giá trị như : count, mean, min, max, std và phần trăm
Ví dụ
# descriptions
print(dataset.describe())
Kết quả :
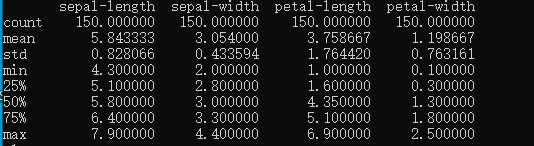
Các giá trị Count, Mean, Median, Mode, Min, Max, std, % là các kỹ thuật thường sử dụng và quan trọng trong Machine Learning, vì vậy việc hiểu các khái niệm này là rất quan trọng cho việc phát triển các dự án về Machine Learning sau này. Chúng tôi sẽ giải thích cho các bạn rõ khái niệm, chi tiết về Count, Mean, Median, Mode, Min, Max, std, % là gì ở các bài tiếp theo về Machine Learning.
5.5 Phân phối, phân bố dữ liệu (Class Distribution)
Chúng ta có thể xem sự phân bổ, phân bố dữ liệu của mỗi class như sau.
Ví dụ
# class distribution
print(dataset.groupby('class').size())
Kết quả :
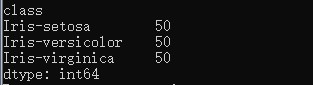
5.6 Toàn bộ code python cho ví dụ về Load dữ liệu và xử lý dữ liệu dataset ở trên như sau:
Ví dụ
# Load libraries
from pandas import read_csv
# Load dữ liệu dataset
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/iris.csv"
names = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
dataset = read_csv(url, names=names)
# shape : Xem kích thước của tập dữ liệu
print(dataset.shape)
# head : Xem dữ liệu của 15 dòng đầu tiên.
print(dataset.head(15))
# Xem tất cả dataset
print(dataset)
# descriptions : Thống kê các giá trị Min, Max, Mean, %, Std
print(dataset.describe())
# class distribution : xem sự phân phối, phân bố dữ liệu của class
print(dataset.groupby('class').size())
6. Data Visualization: Biểu diễn dữ liệu trực quan bằng đồ thị.
Việc load dữ liệu và xử lý dữ liệu dataset ở trên đã cho bạn hiểu và hình dung được về xử lý dữ liệu trong Machine Learning. Tuy nhiên chúng ta có thể trực quan hóa bằng cách biểu diễn biểu đồ để cho người dùng dễ nhìn và dễ hiểu hơn.
Chúng ta sẽ biểu diễn 2 loại biểu đồ:
Univariate Plots : Đây là biểu đồ đơn biến, dùng để biểu thị và hiểu rõ hơn về mỗi thuộc tính.
Multivariate Plots : Đây là biểu đồ đa biến, dùng để biểu thị và hiểu rõ về mối quan hệ giữa các thuộc tính.
6.1 Univariate Plots
6.2 Multivariate Plots
7. Train/Test Model và Evaluate Some Algorithms : Xây dựng hình dữ liệu Model và sử dụng các thuật toán để đào tạo và kiểm tra Model.
8. Make Predictions: Đánh giá các thuật toán và đưa gia dự đoán kết quả.