Machine Learning Train/Test
Machine Learning Train/Test là gì ?
Machine Learning Train/Test là một phương pháp dùng để đánh giá đo sự chính xác của mô hình model.Nó được gọi là Train/Test là bởi vì nó được chia thành 2 tập dữ liệu: tập dữ liệu huấn luyện (Train) và tập thử nghiệm, kiểm tra (Test).
Tập dữ liệu dùng để huấn luyện (Train set) là 80%.
Tập dữ liệu dùng để thử nghiệm kiểm tra (Test set) là 20%.
Train model có nghĩa là chúng ta tạo mô hình model.
Test model có nghĩa là chúng ta kiểm tra sự chính xác của mô hình model.
Các bước Train/Test.
Giả sử chúng ta có tập dữ liệu là 100 khách hàng vào trong một cửa hàng để mua sắm.Chúng ta sẽ dự đoán số tiền của khách hàng sẽ sử dụng để mua hàng trong một khoảng thời gian.
Bởi vì không có dữ liệu thực tế cho nên tôi tạo dữ liệu ngẫu nhiên để mô tả cho bài toán này.
Bước 1: Thu thập dữ liệu
Tập dữ liệu x thể hiện cho thời gian trước khi họ mua hàng.
x = numpy.random.normal(3, 1, 100)
Tập dữ liệu y thể hiện cho số tiền họ đã chi cho việc mua hàng.
y = numpy.random.normal(150, 40, 100)
Bước 2: Chia tập dữ liệu Train/Test.
Tập dữ liệu dùng để huấn luyện (Train) là chọn 80% của dữ liệu ban đầu.
train_x = x[:80]
train_y = y[:80]
Tập dữ liệu thử nghiệm, kiểm tra (Test) là chọn 20% dữ liệu còn lại.
test_x = x[80:]
text_y = y[80:]
Bước 3: Hiển thị tập dữ liệu bằng cách vẽ biều đồ phân tán
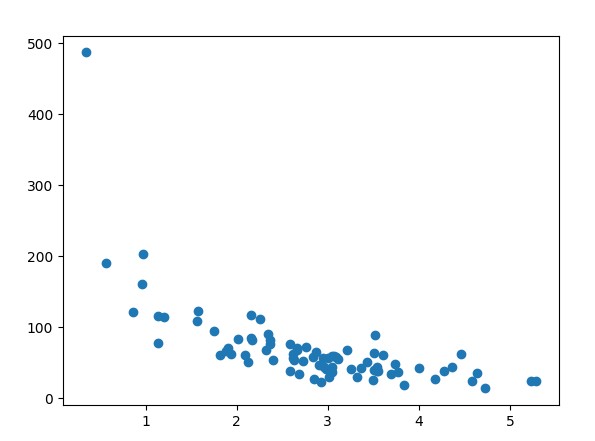
Hiển thị tất cả tập dữ liệu bằng cách vẽ biểu đồ phân tán.
Ví dụ
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
plt.scatter(x, y)
plt.show()
Kết quả :
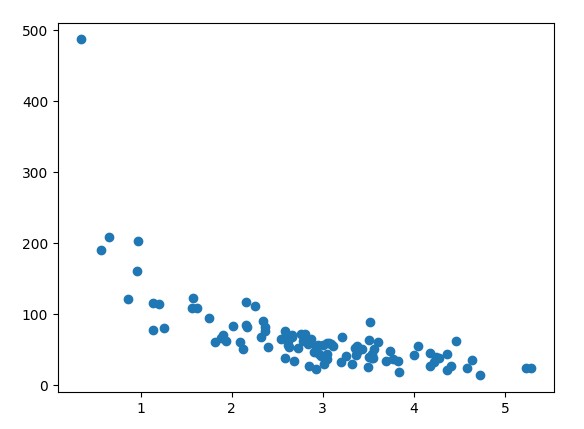
Hiển thị tập dữ liệu huấn luyện (Train set) bằng cách vẽ biểu đồ phân tán.
Ví dụ
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
train_x = x[:80]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
plt.scatter(train_x, train_y)
plt.show()
Kết quả :
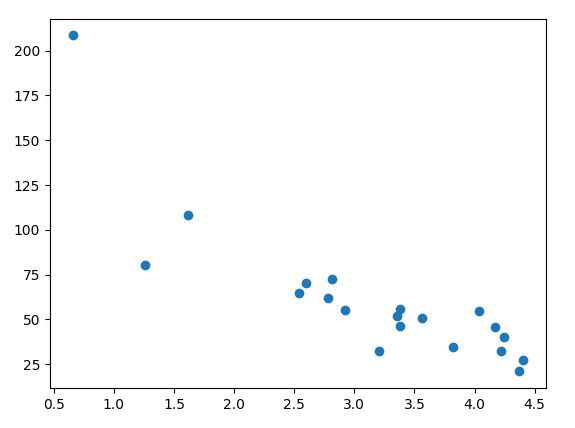
Hiển thị tập dữ liệu thử nghiệm (Test set) bằng cách vẽ biểu đồ phần tán.
Ví dụ
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
train_x = x[:80]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
plt.scatter(test_x, test_y)
plt.show()
Kết quả :
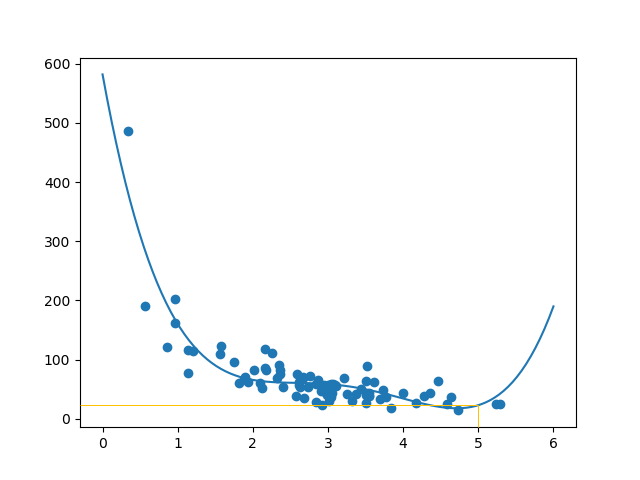
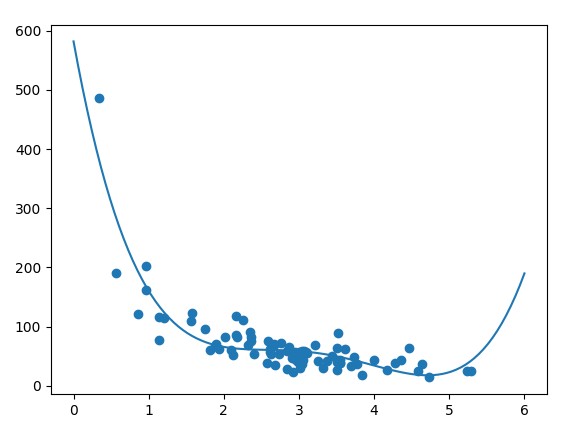
Bước 4: Lựa chọn mô hình model để huấn luyện.(Fit Data set)
Dựa vào biểu đồ phân tán ở bước 3 chúng ta thấy tập dữ liệu phân tán có dạng đường cong, do đó chúng ta sẽ sử dụng thuật toán polynomial regression để tạo và huấn luyện mô hình model.
Ví dụ
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
train_x = x[:80]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4))
myline = numpy.linspace(0, 6, 100)
plt.scatter(train_x, train_y)
plt.plot(myline, mymodel(myline))
plt.show()
Kết quả :
Bước 5: Đánh giá mô hình model.
Sau khi huấn luyện (Train) và tạo mô hình model xong chúng ta cần đánh giá xem mô hình có phù hợp và tốt hay không.
Trong module sklearn của python có phương thức r2_score() để đánh giá mô hình model.
Phương thức r2_score() dùng để đo, đánh giá mối quan hệ giữa trục x và trục y.Hàm r2_score() trả về giá trị nằm trong khoảng từ 0 đến 1, với giá trị 0 có nghĩa là không có mối quan hệ, với giá trị là 1 có nghĩa là mô hình phù hợp và tốt 100%.
Áp dụng phương thức r2_score() trong module sklearn để đánh giá mô hình huấn luyện như sau:
Ví dụ
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
train_x = x[:80]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4))
myline = numpy.linspace(0, 6, 100)
plt.scatter(train_x, train_y)
plt.plot(myline, mymodel(myline))
plt.show()
Kết quả :
0.7988
Kết quả huấn luyện là 0.7988 là tương đối tốt, nhưng chúng ta vẫn cần kiểm tra xem nó thực sự tốt và phù hợp hay không.
Bước 6: Kiểm tra sự chính xác của mô hình model (Test).
Sau khi đánh giá mô hình huấn luyện xong chúng ta cần kiểm tra (Test) xem mô hình huấn luyện có phù hợp và thực sự tốt không.Sử dụng tập dữ liệu test để kiểm tra mô hình model.
Áp dụng phương thức r2_score() trong module sklearn để kiểm tra (Test) mô hình huấn luyện như sau:
Ví dụ
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
train_x = x[:80]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
r2 = r2_score(test_y, mymodel(test_x))
print(r2)
Kết quả :
0.8086
Chúng ta thấy kết quả của mô hình huấn luyện phù hợp hớp bộ thử nghiệm, do đó chúng ta có thể sử dụng mô hình model này để dự đoán kết quả.
Bước 7: Dự đoán kết quả.
Kiểm tra và đánh giá mô hình model, nếu mô hình là phù hợp và tốt chúng ta sẽ sử dụng mô hình để dự đoán kết quả.
Chúng ta thấy kết quả kiểm tra test là 0,8068, kết quả này là khá tốt.Vì vậy chúng ta sẽ sử dụng mô hình để dự đoán kết quả.
Ví dụ chúng ta sẽ dự đoán khách hàng sẽ sử dụng bao nhiêu tiền để mua hàng nếu khách hàng đó ở trong cửa hàng thời gian là 5 phút như sau:
Ví dụ
import numpy
import matplotlib.pyplot as plt
numpy.random.seed(2)
x = numpy.random.normal(3, 1, 100)
y = numpy.random.normal(150, 40, 100) / x
train_x = x[:80]
train_y = y[:80]
test_x = x[80:]
test_y = y[80:]
mymodel = numpy.poly1d(numpy.polyfit(train_x, train_y, 4))
print(mymodel(5))
Kết quả :
22.8796
Kết quả là khách hàng sử dụng 22.8796 đô la để mua hàng, với kết quả này chúng ta thấy nó là phù hợp tương ứng trên biểu đồ.