SQL Create Index
Hướng dẫn tạo Index trong SQL Server và tìm hiểu về Clustered indexes, Non-clustered indexes, Unique Index trong SQL Server.
1.SQL Index là gì?
2.Cách tạo Create Index trong SQL Server.
3.Clustered indexes và Non-clustered indexes trong SQL Server.
4.Kiểm tra hiệu suất của Index.
1.SQL Index là gì?
Index trong SQL được sử dụng để truy xuất, truy vấn dữ liệu nhanh hơn.
Index trong SQL là một trường có cấu trúc mà nó được sắp xếp theo thứ tư như danh sách.
Với việc tạo lập chỉ mục Index sẽ giúp truy vấn các cột nhanh hơn bằng cách tạo con trỏ tới nơi dữ liệu được lưu trữ trong cơ sở dữ liệu Database.
Khi nào sử dụng Index?
Lập chỉ mục Index trong SQL Server nhằm mục đích tăng tốc hiệu suất của cơ sở dữ liệu, vì vậy hãy sử dụng lập chỉ mục bất cứ khi nào nó cải thiện đáng kể hiệu suất của cơ sở dữ liệu của bạn. Khi cơ sở dữ liệu của bạn ngày càng lớn hơn, bạn càng thấy được lợi ích từ việc lập chỉ mục.Tuy nhiên bạn cần lưu ý việc cập nhật một bảng có chỉ mục sẽ mất nhiều thời gian hơn so với việc cập nhật một bảng không có chỉ mục (vì các chỉ mục cũng cần được cập nhật).Vì vậy, chỉ tạo chỉ mục trên các cột sẽ được tìm kiếm thường xuyên.
2.Cách tạo Create Index trong SQL Server.
Có 2 loại Index trong SQL Server đó là: Clustered indexes và Non-clustered indexes.
2.1 Tạo Index trong SQL Server như sau:
Lệnh CREATE INDEX được sử dụng để tạo chỉ mục Index trong SQL Server.>
Cú Pháp
CREATE INDEX index_name ON table_name (column 1, column 2...);
CREATE UNIQUE INDEX index_name ON table_name (column 1, column 2...);
Ví dụ tạo index cho cột tên sản phẩm ProductName của bảng sản phẩm Product_t như sau :
Ví dụ
CREATE INDEX index_ProductName ON Product_t(ProductName);
2.2 Xóa Index trong SQL Server
Cú Pháp
DROP INDEX table_name.index_name;
Ví dụ xóa index trong bảng sản phẩm Product_t như sau :
Ví dụ
DROP INDEX Product_t.index_ProductName;
3.Clustered indexes và Non-clustered indexes trong SQL Server
Clustered và Non-clustered đều được lưu trữ và tìm kiếm dưới dạng cây B-Tree, một cấu trúc dữ liệu tương tự như cây nhị phân (Binary Tree).Cây B là “cấu trúc dữ liệu cây tự cân bằng, duy trì dữ liệu được sắp xếp và cho phép tìm kiếm, truy cập tuần tự, chèn và xóa theo thời gian logarit”.Về cơ bản, nó tạo ra một cấu trúc dạng cây để sắp xếp dữ liệu để tìm kiếm nhanh.
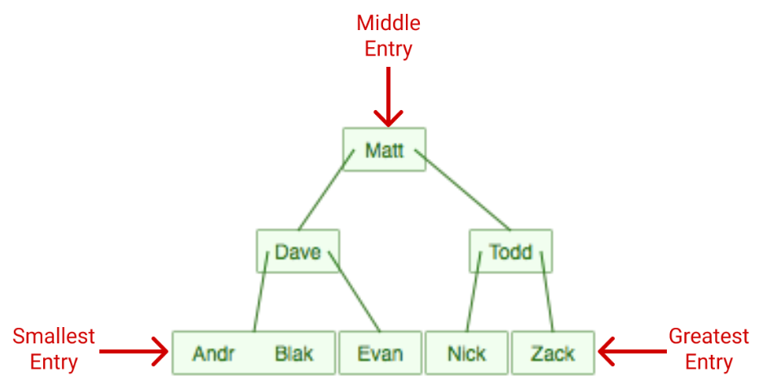
3.1 Clustered indexes
Clustered indexes là chỉ mục Index duy nhất cho mỗi bảng sử dụng khóa chính để sắp xếp dữ liệu trong bảng.
Tạo chỉ mục Clustered index sẽ được tạo tự động khi khóa chính được định nghĩa.
Chúng ta có thể hiểm nôm na Clustered index là tạo index cho cột khóa chính của bảng.
Ví dụ tạo Clustered indexes trong SQL Server.
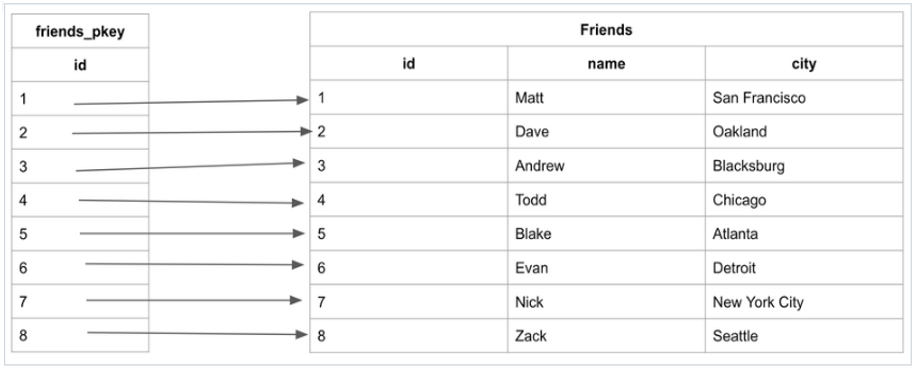
3.2 Non-clustered indexes
Non-clustered indexes là các chỉ mục Index tham chiếu được sắp xếp cho một trường cụ thể, từ bảng chính, giữ các con trỏ quay lại các mục ban đầu của bảng.
Bạn có thể hiểu nôm na Non-clustered indexes là tạo index cho cột cần sắp xếp mà nó không phải là cột khóa chính.
Ví dụ tạo Non-clustered indexes trong SQL Server.
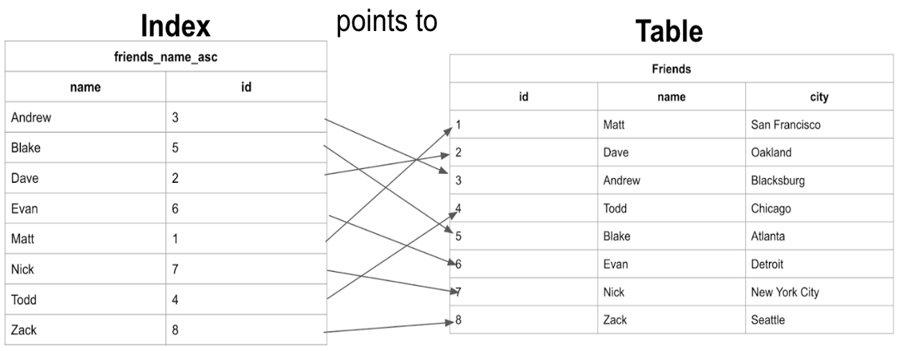
4.Kiểm tra hiệu suất của Index trong SQL Server.
Để kiểm tra hiệu suất và hiệu quả của việc tạo chỉ mục Index các bạn xem ví dụ dưới đây.
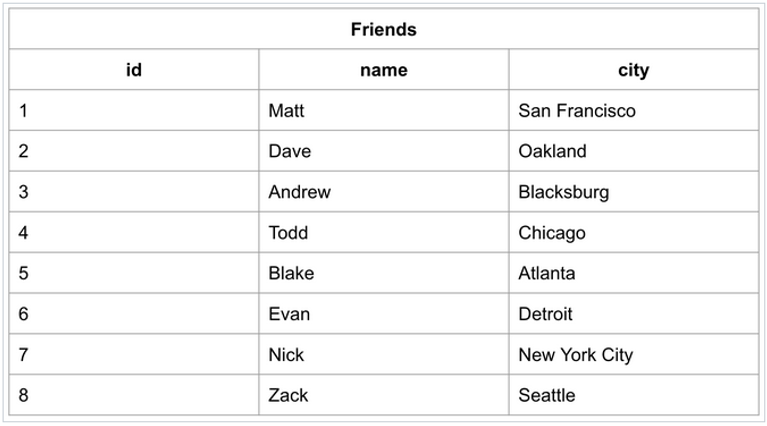
Giả sử chúng ta có bảng Friends chứa thông tin dữ liệu về những người bạn và chúng ta cần tìm bạn có tên là ‘Zack’.
Bảng Friends có dữ liệu như sau:
Câu lệnh SQL tìm kiếm bạn có tên là Zack như sau:
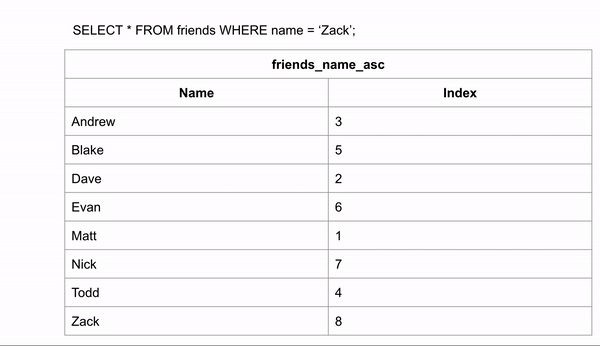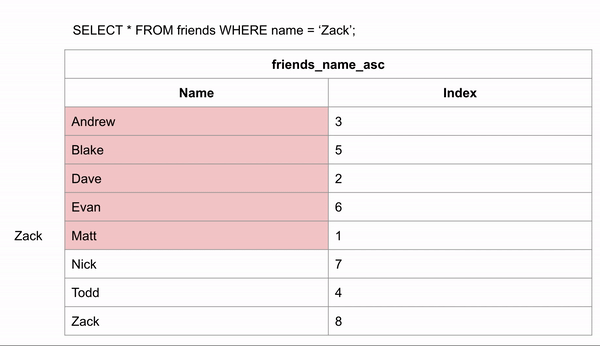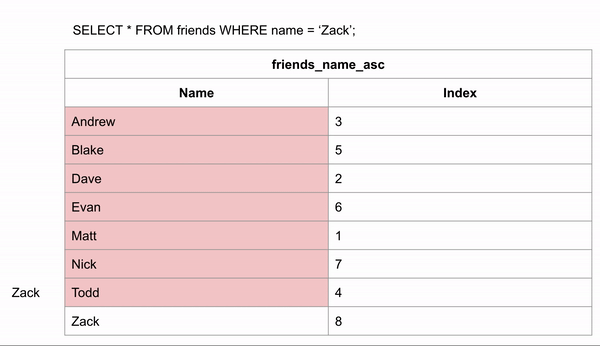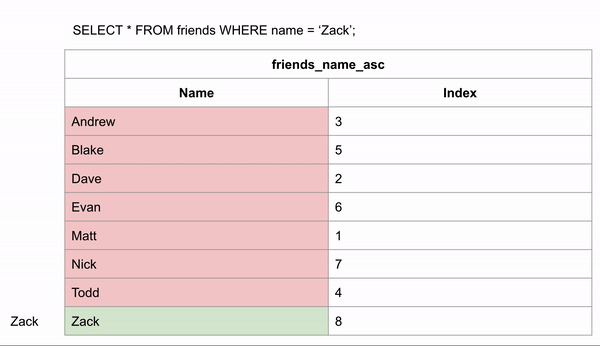
SELECT * FROM Friends WHERE name='Zack';
Hãy tưởng tượng khi bạn muốn tìm một phần thông tin trong cở sở dữ liệu lớn (Big Data).Để lấy thông tin này từ cơ sở dữ liệu, máy tính sẽ tìm kiếm và duyệt qua từng dòng cho đến khi tìm thấy nó.Nếu dữ liệu bạn đang tìm kiếm nằm ở cuối thì truy vấn này sẽ mất nhiều thời gian để chạy.
Bạn có thể hình dung nó tìm kiếm như sau:
Nếu bảng friends chưa tạo Index cho trường name, thì khi tìm kiếm nó sẽ phải tìm kiếm tuyến tính duyệt từng dòng bản ghi cho tới khi tìm thấy nó (Tìm Zack phải duyệt qua 8 dòng).
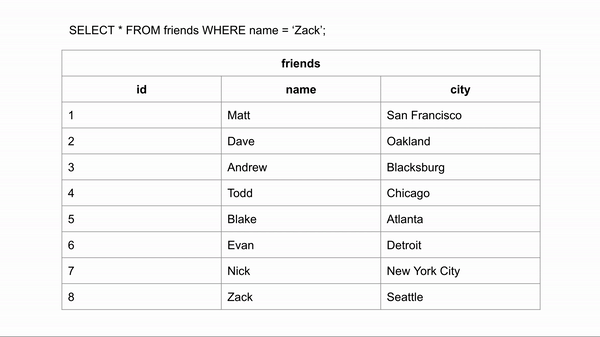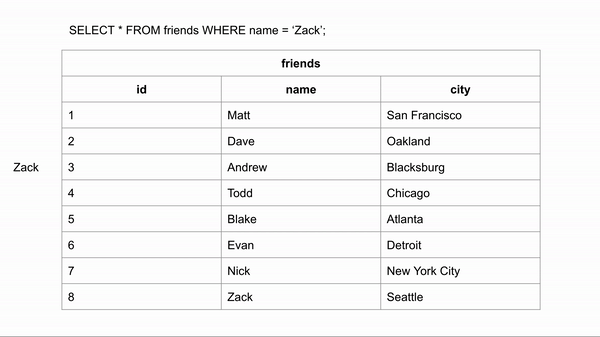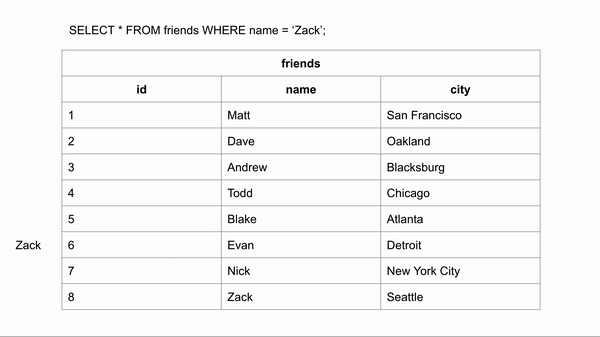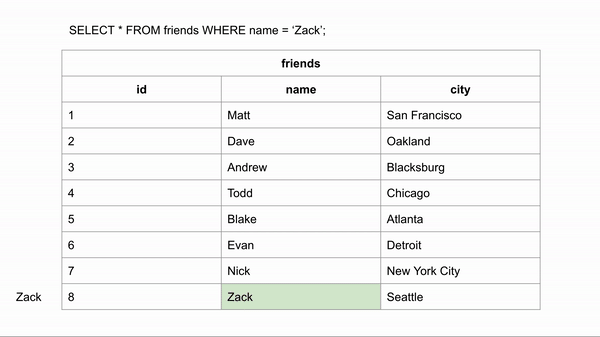
Sau khi tạo Index cho trường name của bảng friends chúng ta hình dung dữ liệu khi tìm kiếm được sắp xếp như sau:
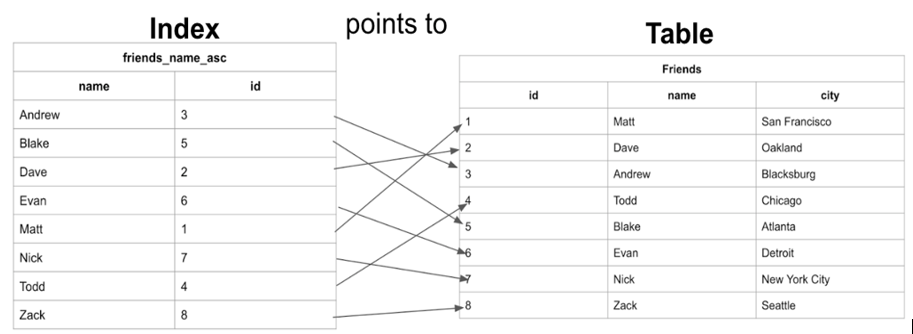
Ở đây chúng ta có thể thấy rằng bảng có dữ liệu được lưu trữ được sắp xếp theo id tăng dần dựa trên thứ tự dữ liệu được thêm vào và Index name có các tên được lưu theo thứ tự bảng chữ cái Alphabet.
Khi bảng được sắp xếp theo thứ tự bảng chữ cái, việc tìm kiếm tên name có thể diễn ra nhanh hơn rất nhiều, vì chúng ta có thể sử dụng thuật toán tìm kiếm nhị phân (binary search), bỏ qua việc tìm kiếm dữ liệu ở một số hàng nhất định.Nếu chúng ta muốn tìm kiếm “Zack” và chúng ta biết dữ liệu theo thứ tự bảng chữ cái, chúng ta có thể nhảy xuống giữa dữ liệu để xem Zack đứng trước hay sau hàng đó.Sau đó chúng ta có thể phân nửa số hàng còn lại và thực hiện so sánh tương tự.Với cách này tìm Zack chỉ cần so sách 3 lần so sánh tương đương với 3 dòng là tìm được kết quả và cách tìm kiếm không có index ở trên thì cần duyệt qua 8 dòng.Như vậy các bạn có thể thấy tạo Index tìm kiếm sẽ nhanh hơn.
Lưu ý:
Các chỉ mục Non-clustered indexes không phải là bảng mới.
Các chỉ mục Non-clustered indexes giữ trường mà chúng chịu trách nhiệm sắp xếp và một con trỏ từ mỗi mục đó quay lại mục nhập đầy đủ trong bảng.
Bạn có thể hình dung và tưởng tượng coi những điều này giống như các chỉ mục trong một cuốn sách.